
2026年1月28日,当《Nature》杂志以谷歌DeepMind的AlphaGenome作为封面故事时,全球生物医学界再次见证了人工智能改写科学研究范式的历史时刻。这个能够一次性处理100万个碱基对序列的AI模型,正在解决困扰遗传学家数十年的难题,那些占据人类基因组98%的"非编码DNA",终于开始露出它们隐藏的秘密。

如果说2021年AlphaFold2破译了蛋白质折叠密码,那么AlphaGenome则试图破译基因组的调控语法;前者解决的是"结构预测"问题;后者瞄准的是更复杂的"功能预测"挑战。人类基因组中仅有约2%的区域编码蛋白质,剩余的98%曾被误称为"垃圾DNA",但科学家早已发现,正是这些非编码区域控制着基因的开关、表达强度和时空模式,它们的突变与癌症、神经退行性疾病、先天缺陷密切相关。

从"看见"到"理解"的跨越
AlphaGenome最令人惊讶的能力在于它的输入-输出规模,模型可以接受长达1兆碱基(1 megabase,相当于100万个碱基对)的DNA序列作为输入,并同时预测数千种功能基因组轨迹,包括转录因子结合位点、组蛋白修饰、RNA剪接模式、基因表达水平等。这相当于让AI同时阅读一本百科全书并预测其中每个段落的功能?
传统的基因组功能预测工具往往聚焦于单一任务,比如预测启动子位置或转录因子结合,而AlphaGenome采用统一的序列到功能框架,一次性输出多维度的功能注释。DeepMind研究团队在Nature论文中指出,这种"瑞士军刀式"的设计使得AlphaGenome不仅能预测单个碱基突变的影响,还能理解远距离调控元件之间的相互作用,这正是基因调控网络的核心特征。
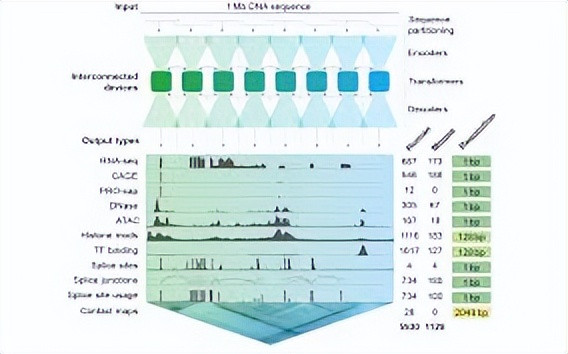
在技术架构上,AlphaGenome采用了类似U-Net的卷积神经网络结构,结合Transformer的注意力机制来捕捉长程依赖关系。模型在包含UK Biobank的15万个全基因组序列、GTEx项目的多组织基因表达数据等海量数据上进行训练,学习到了DNA序列与功能之间复杂的映射规律。与早期的Enformer、Basenji2等模型相比,AlphaGenome将上下文窗口从数十万碱基扩展到百万级别,这一跃升使得模型能够捕捉染色体三维结构中的超远程增强子-启动子互作。
揭开遗传病的神秘面纱
AlphaGenome的实际应用价值已经在多个案例中得到验证。在对ClinVar数据库中数千个临床已知致病变异的测试中,AlphaGenome成功识别出约75%的调控区域致病突变,这一准确率远超现有工具。更令人振奋的是,模型还预测出了多个实验尚未确认但高度可疑的新致病位点。
在剪接相关疾病研究中,AlphaGenome展现出独特优势,RNA剪接是基因表达调控的关键步骤,剪接位点的单碱基突变可能导致外显子跳读或内含子保留,进而引发遗传性疾病。研究团队发现,约15%至50%的遗传性疾病源于剪接突变,但传统的外显子测序往往会遗漏这些深埋在内含子中的致病变异。AlphaGenome通过预测剪接供体、受体位点的强度变化,可以在基因组尺度上筛查潜在的剪接破坏性突变。
在癌症基因组学领域,AlphaGenome同样表现出色,研究人员利用该模型分析了T细胞急性淋巴细胞白血病的全基因组测序数据,成功识别出位于TAL1基因上游的一个致癌性"超级增强子"形成突变。这个位于非编码区域的单碱基改变创造了一个新的转录因子结合位点,导致TAL1基因异常高表达,最终驱动癌症发生。这类发现在传统基因组分析中极易被忽略,因为它们不改变任何蛋白质序列。
"暗物质"不再暗淡
人类基因组中的非编码区域曾被比喻为宇宙学中的"暗物质",我们知道它们存在、知道它们重要;却不知道它们如何发挥作用。全基因组关联研究(GWAS)发现,超过90%的疾病相关变异位于非编码区域,但将这些统计学信号转化为生物学机制一直是遗传学家面临的巨大挑战。
AlphaGenome为这一问题提供了新的解决思路。模型不仅能预测某个变异是否有功能影响、还能预测它会影响哪个基因、通过什么机制影响。例如,对于一个位于某条染色体上的疾病关联SNP,AlphaGenome可以计算该位点突变后对周围1兆碱基范围内所有基因表达的影响,从而推断真正的致病基因和调控通路。

这种能力在精准医学中有巨大应用前景。以载脂蛋白A1基因(APOA1)启动子突变为例,一个单碱基替换导致患者血液中HDL胆固醇水平极度降低、却没有编码区突变。传统基因诊断很难解释这种表型,但AlphaGenome能够精确预测该突变破坏了转录因子结合导致基因表达下降。类似的案例还包括α-地中海贫血的多聚腺苷酸化信号突变、N-乙酰谷氨酸合成酶(NAGS)基因增强子缺失等罕见遗传病。
从预测走向设计
更前瞻性的应用是合成生物学和基因治疗中的序列设计。AlphaGenome不仅能"读懂"DNA;理论上还能"写"DNA。研究人员已经开始尝试利用模型反向设计调控元件,比如为特定组织设计高效启动子、为基因治疗载体设计精准表达的增强子、为CRISPR基因编辑设计更安全的靶点。
Nature同期发表的两篇姐妹论文展示了这种潜力。一项研究利用序列模型为果蝇胚胎的特定组织设计合成增强子,实验验证表明人工设计的序列能够驱动预期的时空表达模式。另一项研究则将这一技术拓展到哺乳动物细胞,为不同细胞类型量身定制调控元件。AlphaGenome的百万碱基上下文理解能力意味着它可以设计出不仅在局部有效、而且不会干扰远端基因表达的"智能"序列。
挑战与局限
尽管AlphaGenome代表了领域内的重大进步,但研究团队和独立评论者都指出了模型的局限性。首先,AlphaGenome的预测是统计学规律的体现,而非机制性理解,模型可能预测出某个突变会改变基因表达,但无法解释其中的分子机制,比如涉及哪些转录因子、染色质重塑复合物或三维基因组结构变化。
其次,模型在个性化预测上仍有不足。目前的深度学习模型主要捕捉群体水平的序列-功能关系,但人类基因组的变异非常丰富,平均每个人携带约400万个单核苷酸变异。当多个变异同时存在时,它们的组合效应可能呈现非加和性,这种复杂的基因型-表型映射仍然超出了现有模型的能力范围。Nature近期的两项研究表明,包括Enformer在内的顶尖模型在解释个人基因组的转录组变异时准确性有限。
第三,模型的训练数据存在偏倚,现有的基因组和表观基因组数据主要来自欧洲血统人群,这可能导致模型在其他族裔中的预测准确性下降。同时,大多数功能数据来自成年组织,胚胎发育、衰老等特殊生理状态的调控规律可能被低估。
开源的力量
值得注意的是,DeepMind在2025年6月就已将AlphaGenome的模型权重和推理代码公开,允许学术界和非商业机构自由使用,2026年1月28日STAT News报道称,DeepMind进一步开放了模型的训练源代码,极大降低了其他研究团队改进和定制模型的门槛。这种开放策略与AlphaFold形成了延续,后者的开源释放了全球数亿蛋白质结构的预测结果,加速了新药研发和基础生物学研究。
已经有多个团队开始基于AlphaGenome开发下游应用;斯坦福大学的研究者正在使用模型优化CAR-T细胞治疗的基因线路设计,哈佛医学院的团队则将其整合到罕见病的遗传诊断流程中。更广泛的应用场景还包括作物基因组改良、合成生物学底盘设计等。有评论指出,AlphaGenome可能成为"DNA领域的ChatGPT",为非专业人员降低基因组分析的技术壁垒。
下一个前沿在哪里
从AlphaFold到AlphaGenome,DeepMind在生命科学领域的连续突破展现了AI与生物学深度融合的威力。但基因组的秘密远未被完全破译、目前的模型仍然主要聚焦于单细胞类型、单一维度的功能预测,而真实生命系统中的基因调控是动态的、多层次的、高度依赖于细胞内外环境的。
下一代模型需要整合更多维度的信息:三维基因组结构(如染色质环、拓扑关联结构域)、表观遗传修饰的动态变化、RNA-蛋白质相互作用网络、甚至代谢物和信号分子的反馈调控。最近发布的Evo 2模型已经尝试跨越DNA、RNA、蛋白质的界限,构建统一的生物序列基础模型。结合单细胞多组学技术和时间序列数据,未来的AI可能真正实现从基因型到表型的端到端预测。
站在2026年初,当我们回望人类基因组计划完成20多年后的今天,AI正在帮助我们填补那些空白的功能注释;阅读那些曾经无法理解的"暗物质"语言。AlphaGenome登上Nature封面不仅是技术里程碑,更是范式转变的象徵,从实验驱动走向计算驱动,从单基因研究走向全基因组系统理解,从被动解读走向主动设计,这条路,我们才刚刚起步。